Online documentation
This vignette displays pre-computed results. Run the targets pipeline locally for interactive analysis.
Overview
See the Glossary for term definitions used throughout this project.
- Survival analysis of the CoMMpass cohort stratified by clinical and cytogenetic features
- Kaplan-Meier curves with log-rank tests for group comparisons
- Cox proportional hazards models for multivariate analysis
- Forest plots of hazard ratios with 95% confidence intervals
Note: This vignette was built in CI with
sample_limit=20. Local builds default to 200 samples. Numbers below reflect the CI subset.
Overall Survival
Kaplan-Meier estimate of the overall survival function for the full patient cohort.
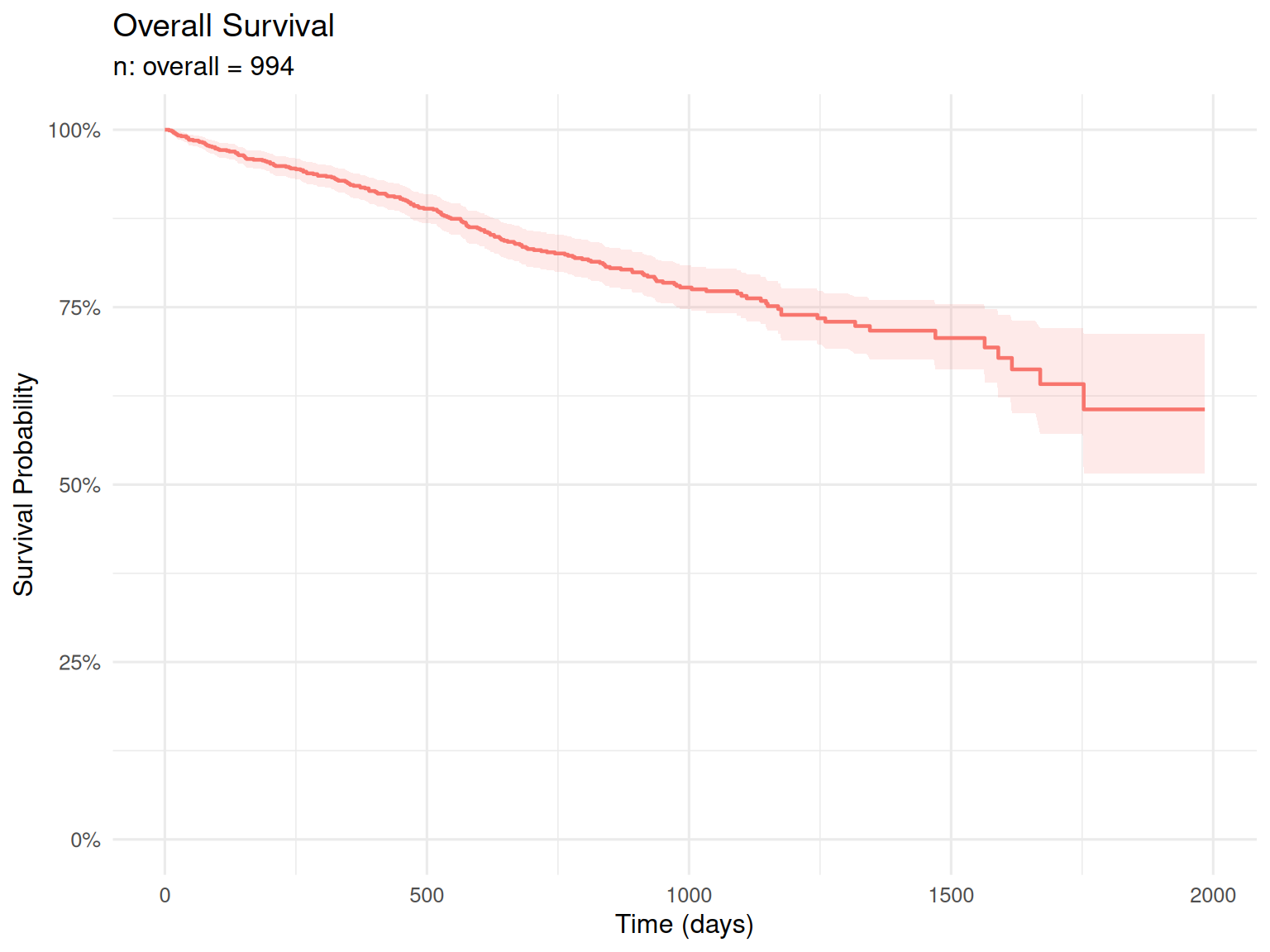
Median overall survival has not been reached in this cohort (n = 994 patients). This indicates that more than 50% of patients remain alive at last follow-up, which is consistent with improving outcomes in multiple myeloma with modern therapies.
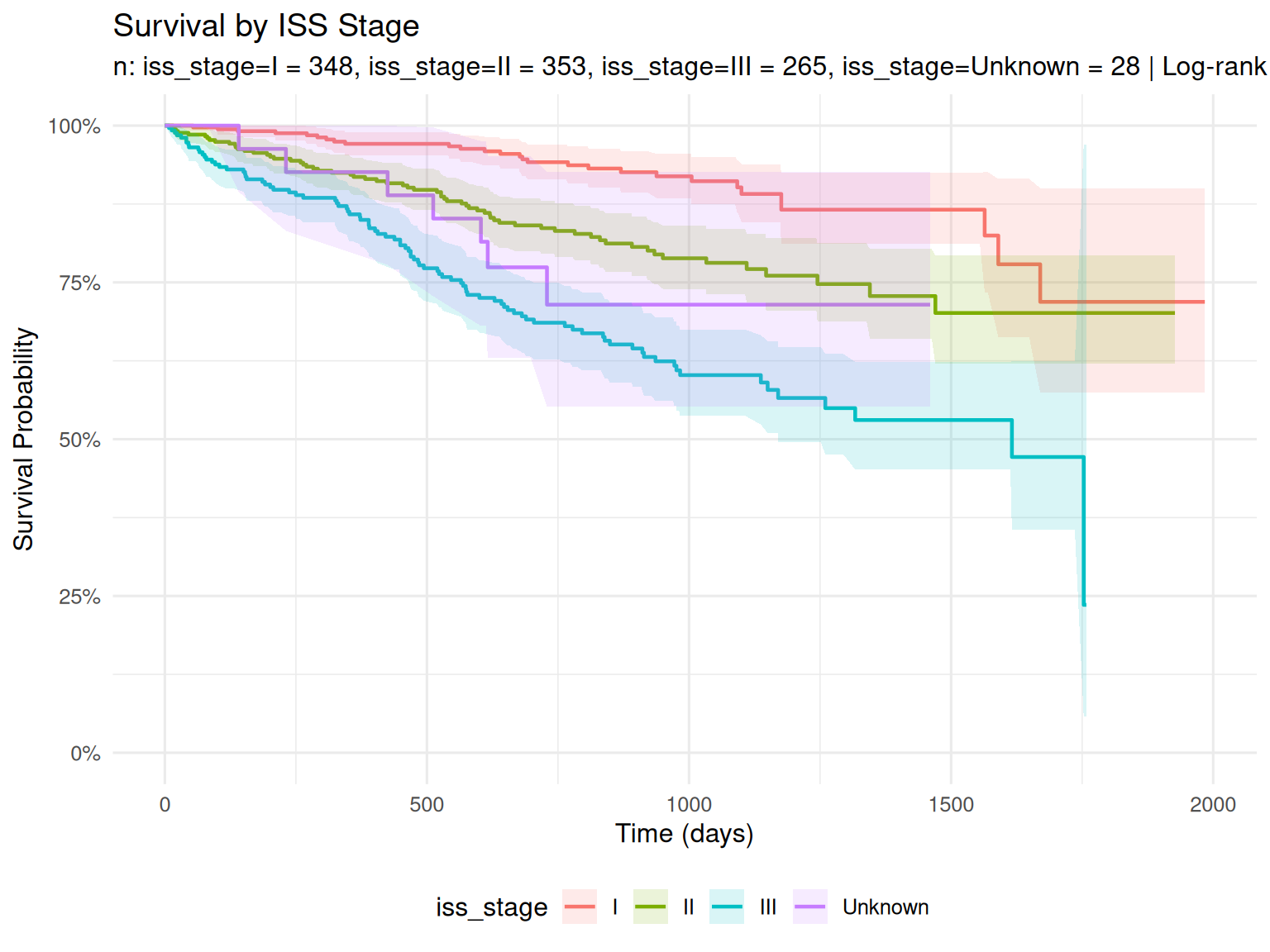
Survival by ISS Stage
- ISS stratifies by serum albumin and beta-2 microglobulin
- ISS III is expected to have worse survival than ISS I
- See the EDA vignette for ISS stage distributions
Survival by Cytogenetic Risk Group
Cytogenetic risk per IMWG 2014 criteria: high-risk = t(4;14) OR t(14;16) OR del(17p); standard-risk = all others.
vig_km_risk returned NULL. See Data Sources.
Survival by Individual Cytogenetic Markers
Each marker is analyzed separately: patients with vs without the alteration.
vig_km_markers returned NULL. See Data Sources.
Cox Proportional Hazards
Basic Model: Age + Gender
Hazard ratios for age and gender from a minimal Cox PH model.
Generating code
{
if (is.null(cox_basic) || is.null(cox_basic$hazard_ratios))
return(NULL)
hr <- cox_basic$hazard_ratios
for (col in names(hr)) {
if (is.numeric(hr[[col]])) {
hr[[col]] <- if (col == "p.value")
signif(hr[[col]], 4)
else round(hr[[col]], 3)
}
}
caption <- paste0("Cox PH model: age + gender. ", "term = covariate name. ",
"HR (hazard ratio) > 1 = increased hazard (worse survival). ",
"CI = 95% confidence interval for HR. ", "p.value = Wald test significance. ",
"n = ", cox_basic$n, " patients, ", cox_basic$n_events,
" events. C-index = ", round(cox_basic$concordance, 3),
". ", "* p < 0.05, ** p < 0.01, *** p < 0.001.")
DT::datatable(hr, rownames = FALSE, filter = "top", options = list(pageLength = 15,
scrollX = TRUE), caption = htmltools::tags$caption(style = "caption-side: top; text-align: left;",
caption))
}| variable | HR | HR_lower | HR_upper | p_value |
|---|---|---|---|---|
| age_years | NA | NA | NA | NA |
| gendermale | 1.466 | 1.078 | 1.992 | 0.015 |
Full Model: Age + Gender + ISS + Cytogenetic Risk
Multivariable Cox model adjusting for ISS stage and IMWG cytogenetic risk classification.
Generating code
{
if (is.null(cox_full) || is.null(cox_full$hazard_ratios))
return(NULL)
hr <- cox_full$hazard_ratios
for (col in names(hr)) {
if (is.numeric(hr[[col]])) {
hr[[col]] <- if (col == "p.value")
signif(hr[[col]], 4)
else round(hr[[col]], 3)
}
}
caption <- paste0("Multivariate Cox PH model with clinical and cytogenetic covariates. ",
"term = covariate name. ", "HR > 1 = increased hazard (worse survival). ",
"CI = 95% confidence interval. ", "n = ", cox_full$n,
" patients, ", cox_full$n_events, " events. ", "C-index = ",
round(cox_full$concordance, 3), ". ", "Covariates: ",
paste(cox_full$covariates_used, collapse = ", "), ".")
DT::datatable(hr, rownames = FALSE, filter = "top", options = list(pageLength = 15,
scrollX = TRUE), caption = htmltools::tags$caption(style = "caption-side: top; text-align: left;",
caption))
}| variable | HR | HR_lower | HR_upper | p_value |
|---|---|---|---|---|
| age_years | NA | NA | NA | NA |
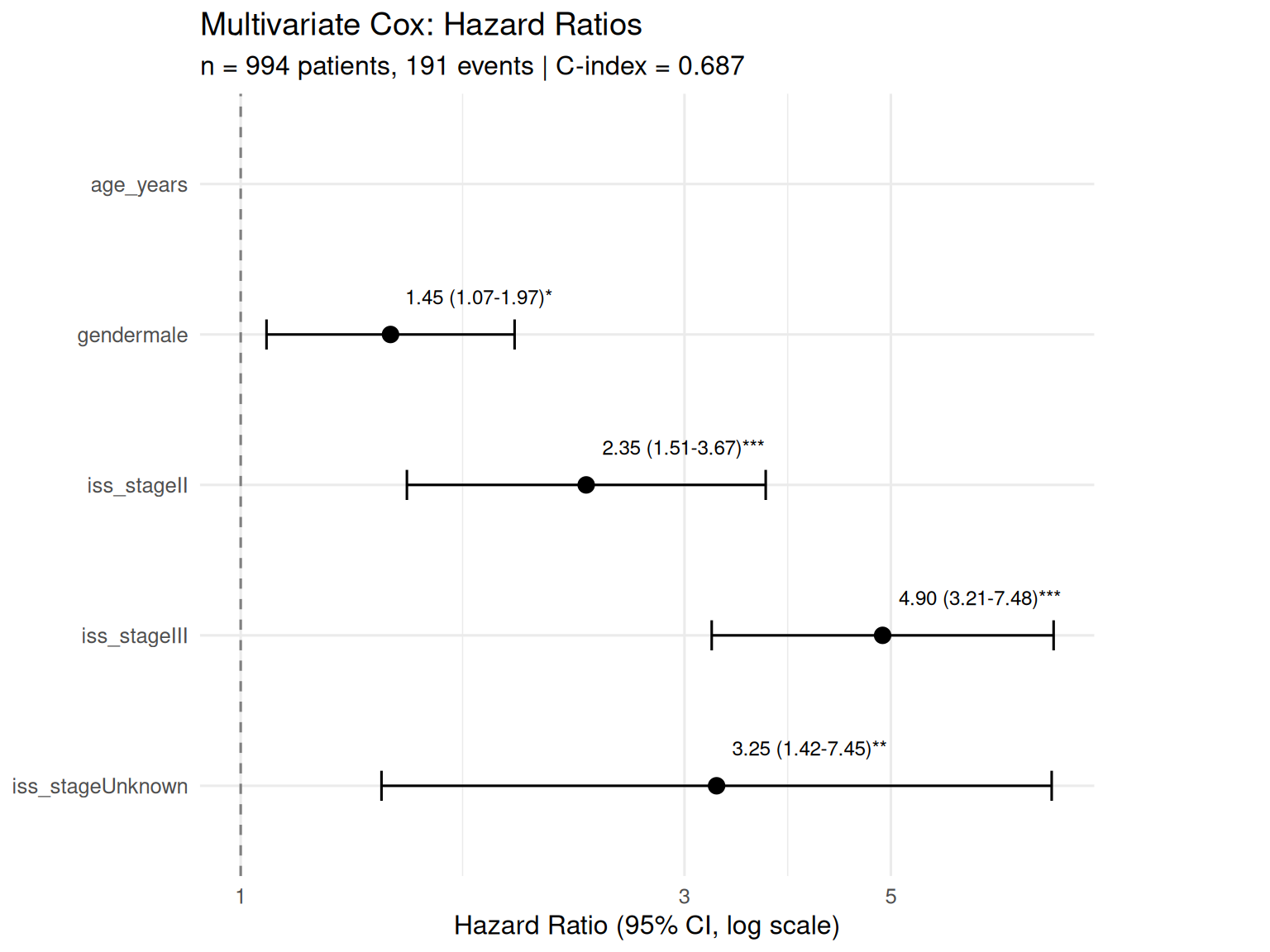
| gendermale | 1.449 | 1.066 | 1.970 | 0.018 |
| iss_stageII | 2.352 | 1.509 | 3.668 | 0.000 |
| iss_stageIII | 4.899 | 3.209 | 7.481 | 0.000 |
| iss_stageUnknown | 3.248 | 1.417 | 7.445 | 0.005 |
Forest Plot
Forest plot showing hazard ratios from the full multivariate Cox regression. Each row represents a covariate; the point estimate is the HR with 95% CI bars. HR > 1 indicates increased risk; HR < 1 indicates a protective effect. The dashed vertical line marks HR = 1 (no effect).
Proportional Hazards Assumption
Schoenfeld residuals test for the proportional hazards assumption. A significant p-value (< 0.05) suggests the covariate’s effect changes over time, violating the PH assumption. Covariates that fail this test may need time-varying coefficients or stratification.
Generating code
{
cox_for_ph <- if (!is.null(cox_full))
cox_full
else cox_basic
if (is.null(cox_for_ph) || is.null(cox_for_ph$ph_test))
return(NULL)
ph <- cox_for_ph$ph_test
ph_table <- as.data.frame(ph$table)
ph_table$variable <- rownames(ph_table)
ph_table <- ph_table[, c("variable", "chisq", "p")]
names(ph_table) <- c("Variable", "Chi-squared", "p-value")
ph_table$`Chi-squared` <- round(ph_table$`Chi-squared`, 2)
ph_table$`p-value` <- signif(ph_table$`p-value`, 4)
caption <- paste0("Proportional hazards assumption test (cox.zph). ",
"Variable = covariate tested. ", "Chi-squared = Schoenfeld residual test statistic. ",
"p-value < 0.05 indicates the PH assumption may be violated ",
"(hazard ratio changes over time). ", "If violated, time-varying coefficients or stratification ",
"should be considered.")
DT::datatable(ph_table, rownames = FALSE, filter = "top",
options = list(pageLength = 15, scrollX = TRUE), caption = htmltools::tags$caption(style = "caption-side: top; text-align: left;",
caption))
}| Variable | Chi-squared | p-value |
|---|---|---|
| gender | 0.24 | 0.62140 |
| iss_stage | 6.89 | 0.07555 |
| GLOBAL | 7.06 | 0.13280 |
Model Comparison
Comparison of nested Cox models using likelihood ratio test, AIC, and concordance index. The full model includes ISS stage and cytogenetic risk in addition to age and gender. A significant likelihood ratio test indicates the additional covariates improve model fit.
Generating code
{
if (is.null(cox_basic) || is.null(cox_full))
return(NULL)
if (is.null(cox_basic$concordance) || is.null(cox_full$concordance))
return(NULL)
comp <- data.frame(Model = c("Basic (age + gender)", paste0("Full (",
paste(cox_full$covariates_used, collapse = " + "), ")")),
N = c(cox_basic$n, cox_full$n), Events = c(cox_basic$n_events,
cox_full$n_events), C_index = c(round(cox_basic$concordance,
3), round(cox_full$concordance, 3)), stringsAsFactors = FALSE)
caption <- paste0("Cox model comparison. ", "Model = covariates included. ",
"N = patients with complete data for all covariates. ",
"Events = observed deaths. ", "C-index = concordance statistic ",
"(0.5 = random, 1.0 = perfect discrimination). ", "Higher C-index indicates better prognostic discrimination.")
DT::datatable(comp, rownames = FALSE, filter = "top", options = list(pageLength = 10,
scrollX = TRUE), colnames = c("Model", "N", "Events",
"C-index"), caption = htmltools::tags$caption(style = "caption-side: top; text-align: left;",
caption))
}| Model | N | Events | C_index |
|---|---|---|---|
| Basic (age + gender) | 994 | 191 | 0.545 |
| Full (age_years + gender + iss_stage) | 994 | 191 | 0.687 |
Survival by Gene Expression
Patients are split at the median VST expression of each top DE gene into “High” and “Low” groups. This connects differential expression results to clinical outcomes.
Note on multiple testing: With 5 genes tested, a Bonferroni-corrected significance threshold is p < 0.01.
Expression by Cytogenetic Subtype
Violin/box plots showing gene expression (VST) stratified by cytogenetic marker status. This reveals whether specific alterations drive expression changes in top DE genes.
Next Steps
- Time-varying coefficients: For covariates violating the PH assumption.
- Cure models: If a plateau is observed in KM curves, consider mixture cure models.
- See the cytogenetic landscape for alteration frequencies underlying risk groups.
- See the DE results for gene signatures that could inform survival stratification.
Data Sources
Results in this vignette are derived from the MMRF CoMMpass study (MMRF-COMMPASS, ~1,143 patients), downloaded via TCGAbiolinks. The pipeline runs with a configurable sample_limit (default 200; CI uses 20).
For full citations, data access tiers, and the distinction between pipeline data and synthetic test data, see the Data Sources vignette.
Recent Changes
Recent project commits with lines added, files changed, and change categories.
| date | type | summary | n_files | lines_added | lines_removed | file_categories |
|---|---|---|---|---|---|---|
| 2026-03-14 | Bug Fix | fix(pipeline): Fix 11 NULL targets — DE condition, ID matching, consensus type | 41 | 146 | 47 | Other, R Source |
| 2026-03-14 | Bug Fix | fix(cachix): Remove –watch-mode auto flag (already default) | 1 | 1 | 1 | Other |
| 2026-03-14 | Bug Fix | fix(pipeline): Fix 3 NULL-target bugs, auto-generate package.nix (#93) | 87 | 235 | 80 | Config, Docs, Other, R Source |
| 2026-03-14 | Bug Fix | fix(nix): Fix cachix signing key, rebuild Bioconductor-dependent targets | 2 | 0 | 0 | Other |
| 2026-03-14 | New Feature | feat(captions): Add dynamic captions to 34 table/plot targets | 22 | 579 | 89 | Other, R Source |
| 2026-03-14 | Bug Fix | fix(vignettes): Enforce zero-computation rule — 22 violations → 0 | 32 | 360 | 764 | Other, R Source, Vignettes |
| 2026-03-13 | Bug Fix | fix(vignettes): Convert kable RDS to data.frames, fix telemetry eval guards | 18 | 8 | 2 | Other, Vignettes |
| 2026-03-13 | Bug Fix | fix(ci): Save data frames (not DT widgets) to RDS for Nix portability | 3 | 0 | 0 | Other |
| 2026-03-13 | Bug Fix | fix(vignettes): Use Quarto #| eval syntax for pkgdown-banner chunks | 11 | 44 | 11 | Vignettes |
| 2026-03-13 | Refactoring | refactor(targets): Move Bioconductor packages to per-target declarations | 11 | 35 | 17 | Other, R Source, Vignettes |
| 2026-03-13 | New Feature | feat(vignettes): Add code provenance, kable→DT conversion, caption compliance | 35 | 1004 | 437 | CI/CD, Other, R Source, Vignettes |
| 2026-03-13 | Bug Fix | fix(vignettes): Skip NULL RDS in safe_tar_read, return invisible(NULL) | 11 | 22 | 22 | Vignettes |
| 2026-03-13 | Bug Fix | fix(glossary): Prevent double DT::datatable() wrapping in glossary-table chunk | 1 | 3 | 1 | Vignettes |
| 2026-03-13 | CI/CD | ci: Show quarto errors with quiet=FALSE, render individual vignettes in diagnostic | 1 | 20 | 6 | CI/CD |
| 2026-03-13 | CI/CD | ci: Add verbose quarto error diagnostics on build failure | 1 | 14 | 1 | CI/CD |
| 2026-03-13 | Bug Fix | fix(vignettes): Strip Nix paths from DT widgets, auto-wrap data frames | 25 | 66 | 28 | CI/CD, Other, Vignettes |
| 2026-03-13 | CI/CD | ci: Add diagnostic quarto render step to debug build failure | 1 | 17 | 0 | CI/CD |
| 2026-03-13 | Bug Fix | fix(vignettes): Revert safe_tar_read placeholder, guard gene-report | 11 | 12 | 56 | Vignettes |
| 2026-03-13 | Maintenance | chore: Export vig_count_distribution_plot as ggplot RDS (513KB) | 1 | 0 | 0 | Other |
| 2026-03-13 | Bug Fix | fix(vignettes): Enable code eval in CI with RDS fallback | 80 | 113 | 74 | CI/CD, Other, R Source, Vignettes |
Bayesian Survival Models
Bayesian Cox PH models fit with brms using weakly informative priors. These complement the frequentist models above by providing posterior distributions, credible intervals, and natural hierarchical structure (e.g., ISS-stage random intercepts).
Note
Bayesian models use
cue = "never"— they only run when explicitly requested viatar_make(names = bayes_cox_basic). MCMC compilation takes several minutes.
Frequentist vs Bayesian Comparison
| Covariate | Freq_HR | Freq_CI | Freq_p | Bayes_HR | Bayes_CI |
|---|---|---|---|---|---|
| age_years | NA | [NA, NA] | NA | 1.010 | [0.143, 7.711] |
| gendermale | 1.466 | [1.078, 1.992] | 0.0147 | 1.458 | [1.071, 1.996] |
Reproducibility
Session Info (click to expand)
Show code
sessionInfo()
#> R version 4.5.3 (2026-03-11)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.3 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
#> [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
#> [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> loaded via a namespace (and not attached):
#> [1] base64url_1.4 gtable_0.3.6 jsonlite_2.0.0
#> [4] dplyr_1.2.0 compiler_4.5.3 tidyselect_1.2.1
#> [7] callr_3.7.6 scales_1.4.0 yaml_2.3.12
#> [10] fastmap_1.2.0 ggplot2_4.0.2 R6_2.6.1
#> [13] generics_0.1.4 igraph_2.2.2 knitr_1.51
#> [16] backports_1.5.0 targets_1.12.0 tibble_3.3.1
#> [19] pillar_1.11.1 RColorBrewer_1.1-3 rlang_1.1.7
#> [22] xfun_0.57 S7_0.2.1 otel_0.2.0
#> [25] cli_3.6.5 withr_3.0.2 magrittr_2.0.4
#> [28] ps_1.9.1 digest_0.6.39 grid_4.5.3
#> [31] processx_3.8.6 secretbase_1.2.0 lifecycle_1.0.5
#> [34] prettyunits_1.2.0 vctrs_0.7.2 evaluate_1.0.5
#> [37] glue_1.8.0 data.table_1.18.2.1 farver_2.1.2
#> [40] codetools_0.2-20 rmarkdown_2.30 tools_4.5.3
#> [43] pkgconfig_2.0.3 htmltools_0.5.9